> ## Documentation Index
> Fetch the complete documentation index at: https://platform.stepfun.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Streaming Text-to-Speech
This API allows you to generate audio using our Streaming Text-to-Speech (TTS) model.
## Request Method
WebSocket
## Endpoint
`wss://api.stepfun.ai/v1/realtime/audio`
For Step Plan, use `wss://api.stepfun.ai/step_plan/v1/realtime/audio`
## Request Headers
* `Authorization` `string` **required**
The API key used for authentication. Its value should be: `Bearer STEP_API_KEY`.
## Request Body
* `model` `string` **required**
The name of the model to use. Currently supports `step-tts-2` and `stepaudio-2.5-tts`.
The `step-tts-vivid` model name is deprecated but existing user requests will continue to be supported.
Note: The `stepaudio-2.5-tts` model may produce significantly lower quality results in WebSocket streaming mode compared to non-streaming HTTP requests. If latency is not a concern, we recommend using the standard non-streaming speech synthesis API.
## Call Instructions
To generate audio in streaming mode, you must send the corresponding Client Event after the WebSocket connection is successfully established. The server will then return the corresponding Server Event, through which the audio is generated.
If there is no activity for 60 consecutive seconds, the system will automatically close the connection.
### Client Event & Server Event Mapping
A detailed description can be found in the explanation below.
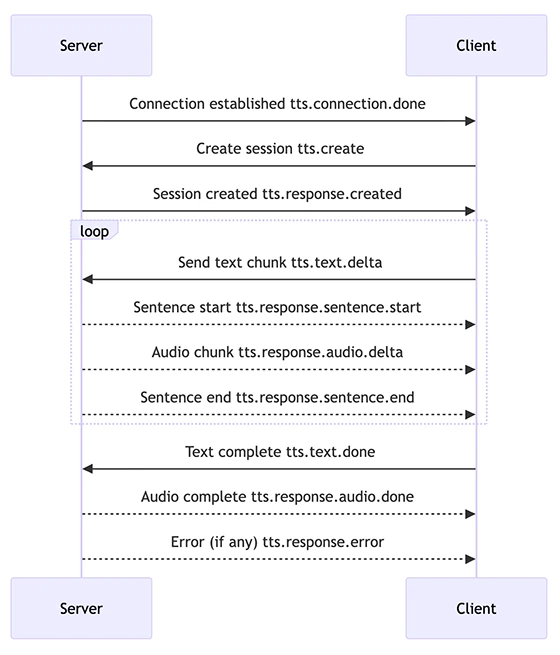 | Message Type | Client Event | Server Event | Description |
| ---------------------- | -------------- | --------------------------- | --------------------------------------------------------------------------------------------------------------------- |
| Connection Established | - | tts.connection.done | Sent by the server after the WebSocket connection is successfully established. |
| Create Session | tts.create | tts.response.created | Creates a new session. After receiving this response, the client may proceed with generation. |
| Sentence Start | - | tts.response.sentence.start | Triggered when accumulated text meets the generation threshold and sentence generation begins. |
| Send Text | tts.text.delta | tts.response.audio.delta | Sends text increments. The corresponding audio delta is returned and can be played immediately. |
| Sentence End | - | tts.response.sentence.end | Triggered when accumulated text meets the end-of-sentence condition. |
| Flush Buffer | tts.text.flush | tts.text.flushed | Quickly clears the buffer and returns all remaining audio that has not yet been sent. |
| Text Done | tts.text.done | tts.response.audio.done | Marks the end of this generation task. No further audio will be produced, and the server will release the connection. |
| Audio Error | - | tts.response.error | Returned when audio generation encounters an error. |
## Client Event Details
### Create Session `tts.create`
The event used to create a new session. After the WebSocket connection is established and the `tts.connection.done` Server Event is received, the client should send this event to initiate audio generation.
* `type` `string` **required**
Must be set to `tts.create`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID used to identify which conversation the request belongs to. Returned by the `tts.connection.done` Server Event.
* `voice_id` `string` **required**
The ID of the voice to use. Refer to the System Voice ID List for supported voices and samples.
* `response_format` `string` **optional**
The audio format. Supported values are: `wav`, `mp3`, `flac`, `opus`, `pcm`. Also supports streaming variants: `mp3_stream`, `opus_stream`, `flac_stream`. Defaults to `mp3`.
* `sample_rate` `int` **optional**
The sampling rate of the output audio. Supported values: `8000`, `16000`, `22050`, `24000`, `48000`. Default: `24000`.
* `pronunciation_map` `object array` **optional**
Defines a pronunciation rule to annotate or override the reading of specific characters or symbols. In Chinese text, tones are represented by numbers: 1 for the first tone, 2 for the second tone, 3 for the third tone, 4 for the fourth tone, and 5 for the neutral tone.
* `tone` `string` **required**
Specific pronunciation mapping rules, separated by `/`. Example: `["omg/oh my god"]`.
* `speed_ratio` `float` **optional**
The speaking rate. Valid range: 0.5 to 2.0. Default: 1.0.
* `volume_ratio` `float` **optional**
The volume level. Valid range: 0.1 to 2.0. Default: 1.0.
* `mode` `string` **optional**
The generation mode. Supported values: `default` (character-level generation, suitable for LLM real-time streaming scenarios) and `sentence` (sentence-level generation, suitable when full sentences are already prepared). Default: `default`.
* `instruction` `string` **optional**
Global natural language guidance. Only effective when connected to the `stepaudio-2.5-tts` model. Used to set the overall emotional tone for the session. Maximum length: 200 characters.
* `markdown_filter` `bool` **optional**
Whether to enable Markdown filtering for the input text.
* `voice_label` `object` **optional**
Voice tags. Required when using a custom voice. Only one of the following fields can be set at a time: `language`, `emotion`, or `style`.
* `language` `string` **optional**
The language tag. Supported values: `Cantonese`, `Sichuanese`, `Japanese`. If not specified, the system will automatically determine whether the input text is English or Chinese.
* `emotion` `string` **optional**
Emotion tag. Supports up to 11 options such as `Happy`, `Angry`, etc. Supported values may vary by model.
* `style` `string` **optional**
Speaking or delivery style. Supports up to 17 styles. Supported values may vary by model.
⚠️ Note: The `stepaudio-2.5-tts` model does not support this field. If you are using `stepaudio-2.5-tts`, do not pass `voice_label`. Use the `instruction` field to control emotion and style instead. For other models, refer to the [Voice Tags List](/en/guides/developer/tts#voice-tags-list).
Default mode is designed for scenarios where TTS is used together with a large language model. In this mode, the system automatically buffers and segments sentences. Therefore, it does not return audio immediately; generation begins only when the accumulated input forms a complete sentence. If you need to force an immediate return, you can send `tts.text.flush`, and the model will promptly return the available audio.
Sentence mode is suitable for scenarios where the full text is already available. In this mode, the system automatically segments the text based on punctuation marks such as `. ! ?` and generates audio accordingly.
Example:
```json theme={null}
{
"type": "tts.create",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"voice_id": "lively-girl",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000,
"pronunciation_map": {
"tone": [
"LOL/laugh out loudly"
]
}
}
}
```
Example (stepaudio-2.5-tts):
```json theme={null}
{
"type": "tts.create",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"voice_id": "cixingnansheng",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000,
"instruction": "Ice-cold tone, strong pressure, slightly slow pace",
"pronunciation_map": {
"tone": [
"LOL/laugh out loudly"
]
}
}
}
```
### Generate Audio `tts.text.delta`
Client Event used to generate audio. During generation, if the TTS engine determines that the conditions for audio generation have been met, it returns a `tts.response.sentence.start` event to indicate that inference has begun. It then returns one or more `tts.response.audio.delta` events containing the audio data. After all audio for the sentence has been sent, the engine returns a `tts.response.sentence.end` event to indicate that the sentence has finished generating.
If the TTS engine determines that the conditions have not been met, no events will be returned.
* `type` `string` **required**
Must be set to `tts.text.delta`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID used to identify which conversation the request belongs to. Returned by the `tts.connection.done` Server Event.
* `text` `string` **required**
The text to be synthesized. The maximum length is 1,000 characters. Supports using `()` to pass non-spoken inline instructions. If the text itself needs to be spoken, do not wrap it in parentheses.
Example:
```json theme={null}
{
"type": "tts.text.delta",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text": "The weather is great today, and I want to learn StepFun large model technologies."
}
}
```
Example (stepaudio-2.5-tts):
```json theme={null}
{
"type": "tts.text.delta",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text": "(excited) The weather is great today, and I want to learn StepFun large model technologies!"
}
}
```
### Flush Buffer `tts.text.flush`
Forces the TTS engine to return all audio generated so far by clearing the internal buffer.
* `type` `string` **required**
Must be set to `tts.text.flush`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID used to identify which conversation the request belongs to. Returned by the `tts.connection.done` Server Event.
Example:
```json theme={null}
{
"type": "tts.text.flush",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0"
}
}
```
### Finish Audio Generation `tts.text.done`
Complete Audio Generation.
* `type` `string` **required**
Must be set to `tts.text.done`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID used to identify which conversation the request belongs to. Returned by the `tts.connection.done` Server Event.
Example:
```json theme={null}
{
"type": "tts.text.done",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0"
}
}
```
## Server Event Details
### Connection Established `tts.connection.done`
Indicates that the WebSocket connection has been successfully established.
* `event_id` `string` **required**
The unique ID of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.connection.done`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID that must be included in subsequent requests.
Example:
```json theme={null}
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.connection.done",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70"
}
}
```
### Session Created `tts.response.created`
Indicates that the session has been successfully created.
* `event_id` `string` **required**
The unique ID of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.created`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID that must be included in subsequent requests.
Example:
```json theme={null}
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.response.created",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70"
}
}
```
### Sentence Start `tts.response.sentence.start`
Indicates that the TTS engine has begun generating a new sentence.
* `event_id` `string` **required**
The unique ID of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.sentence.start`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID for the current conversation.
* `text` `string` **required**
The text content being generated in this sentence.
* `started_at` `string` **required**
The timestamp indicating when sentence generation started.
Example:
```json theme={null}
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.response.sentence.start",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text": "blah blah",
"started_at": 10292929292
}
}
```
### Receive Generated Audio `tts.response.audio.delta`
Indicates that the server is returning a chunk of generated audio.
* `event_id` `string` **required**
The unique identifier of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.audio.delta`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID must be used in subsequent requests.
* `status` `string` **required**
The generation status. Supported values are `unfinished` and `finished`.
* `audio` `string` **required**
The Base64-encoded audio data.
* `duration` `float` **required**
The duration of this audio chunk, in seconds.
Example:
```json theme={null}
{
"event_id": "42bd707a-ba16-4ddb-a751-54d84301b474",
"type": "tts.response.audio.delta",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0",
"status": "unfinished",
"audio": "BASE64 audio data",
"duration": 2.043375
}
}
```
### Sentence End `tts.response.sentence.end`
Indicates that the TTS engine has finished generating a sentence.
* `event_id` `string` **required**
The unique identifier of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.sentence.end`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID.
* `text` `string` **required**
The text content generated for this sentence.
* `ended_at` `string` **required**
The timestamp indicating when the generation of this sentence ended.
Example:
```json theme={null}
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.response.sentence.end",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text": "blah blah",
"ended_at": 10292929292
}
}
```
### Flush Start `tts.text.flushed`
Indicates that the system has received the flush command and has begun clearing the buffer.
* `event_id` `string` **required**
The unique identifier of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.text.flushed`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID that must be included in subsequent requests.
Example:
```json theme={null}
{
"event_id": "01956e8ee1b9788c95d5981b1cfdbf12",
"type": "tts.text.flushed",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0"
}
}
```
### Generation Completed `tts.response.audio.done`
Indicates that the audio generation task has been completed. After receiving this event, the connection will automatically close. Additionally, if the connection remains idle for more than 60 seconds, the system will also complete the generation and close the connection.
* `event_id` `string` **required**
The unique identifier of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.audio.done`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID that must be included in subsequent requests.
* `audio` `string` **required**
The Base64-encoded audio data, containing all audio content generated in this session.
Example:
```json theme={null}
{
"event_id": "01956e8bf5067d6499cdfa0dad34f805",
"type": "tts.response.audio.done",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"audio": ""
}
}
```
### Error Event `tts.response.error`
Indicates that an error occurred during audio generation.
```json theme={null}
{
"event_id": "01956e8fdb157619a852bdf38028db45",
"type": "tts.response.error",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0",
"code": "503",
"message": "The engine is currently overloaded, please try again later",
"details": {
"error": "The engine is currently overloaded, please try again later"
}
}
}
```
## Code Example
First, run `pip install websocket-client`, and then execute the following code.
```python theme={null}
import websocket
import rel
import json
headers = {
"Authorization": "Bearer STEP_API_KEY"
}
def get_start_event(sid):
return json.dumps(
{
"type": "tts.create",
"data": {
"session_id": sid,
"voice_id": "lively-girl",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000
},
}
)
def on_message(ws, message):
data = json.loads(message)
session_id = data["data"]["session_id"]
event_type = data["type"]
if event_type == "tts.connection.done":
start_event = get_start_event(session_id)
ws.send(start_event)
print(message)
def on_error(ws, error):
print(error)
if __name__ == "__main__":
websocket.enableTrace(True)
ws = websocket.WebSocketApp(
"wss://api.stepfun.ai/v1/realtime/audio?model=step-tts-2",
header=headers,
on_message=on_message,
on_error=on_error,
)
ws.run_forever(
dispatcher=rel,
reconnect=5
)
rel.signal(2, rel.abort)
rel.dispatch()
```
```js theme={null}
const WebSocket = require('ws');
const url = 'wss://api.stepfun.ai/v1/realtime/audio?model=step-tts-2';
const headers = {
Authorization: 'Bearer STEP_API_KEY',
'Content-Type': 'application/json',
};
const ws = new WebSocket(url, {
headers: headers
});
ws.on('open', () => {
console.log('Connection established');
});
ws.on('message', (message) => {
console.log(`Message received: ${message}`);
const event = JSON.parse(message);
const session_id = event.data.session_id;
const event_type = event.type;
if (event_type === 'tts.connection.done') {
ws.send(JSON.stringify({
type: 'tts.create',
data: {
session_id: session_id,
voice_id: 'lively-girl',
response_format: 'wav',
volume_ratio: 1.0,
speed_ratio: 1.0,
sample_rate: 16000
}
}));
}
});
ws.on('error', (error) => {
console.error(`Error occurred: ${error}`);
});
ws.on('close', (code, reason) => {
console.log(`Connection closed, code: ${code}, reason: ${reason}`);
});
```
### stepaudio-2.5-tts Code Example (Python)
First, run `pip install websocket-client`, and then execute the following code.
```python theme={null}
import websocket
import rel
import json
headers = {
"Authorization": "Bearer STEP_API_KEY" # Replace with your STEPFUN API KEY
}
def get_start_event(sid):
return json.dumps(
{
"type": "tts.create",
"data": {
"session_id": sid,
"voice_id": "cixingnansheng",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000,
# [New] TTS 2.5 global emotion instruction
"instruction": "Extremely angry tone, strong pressure, slightly fast pace"
},
}
)
def on_message(ws, message):
data = json.loads(message)
session_id = data["data"]["session_id"]
event_type = data["type"]
if event_type == "tts.connection.done":
# 1. Send session creation with global instruction
start_event = get_start_event(session_id)
ws.send(start_event)
# 2. Send text with inline instruction in parentheses (max 1000 chars)
text_event = json.dumps({
"type": "tts.text.delta",
"data": {
"session_id": session_id,
"text": "(slams table) Do you think our technology at StepFun Beijing is a joke?!"
}
})
ws.send(text_event)
# 3. Send flush to force return current audio
flush_event = json.dumps({
"type": "tts.text.flush",
"data": {"session_id": session_id}
})
ws.send(flush_event)
# Print server events (including generated audio data)
print(message)
def on_error(ws, error):
print(error)
if __name__ == "__main__":
websocket.enableTrace(True)
# Use stepaudio-2.5-tts model in the connection URL
ws = websocket.WebSocketApp(
"wss://api.stepfun.ai/v1/realtime/audio?model=stepaudio-2.5-tts",
header=headers,
on_message=on_message,
on_error=on_error,
)
ws.run_forever(
dispatcher=rel,
reconnect=5
)
rel.signal(2, rel.abort)
rel.dispatch()
```
| Message Type | Client Event | Server Event | Description |
| ---------------------- | -------------- | --------------------------- | --------------------------------------------------------------------------------------------------------------------- |
| Connection Established | - | tts.connection.done | Sent by the server after the WebSocket connection is successfully established. |
| Create Session | tts.create | tts.response.created | Creates a new session. After receiving this response, the client may proceed with generation. |
| Sentence Start | - | tts.response.sentence.start | Triggered when accumulated text meets the generation threshold and sentence generation begins. |
| Send Text | tts.text.delta | tts.response.audio.delta | Sends text increments. The corresponding audio delta is returned and can be played immediately. |
| Sentence End | - | tts.response.sentence.end | Triggered when accumulated text meets the end-of-sentence condition. |
| Flush Buffer | tts.text.flush | tts.text.flushed | Quickly clears the buffer and returns all remaining audio that has not yet been sent. |
| Text Done | tts.text.done | tts.response.audio.done | Marks the end of this generation task. No further audio will be produced, and the server will release the connection. |
| Audio Error | - | tts.response.error | Returned when audio generation encounters an error. |
## Client Event Details
### Create Session `tts.create`
The event used to create a new session. After the WebSocket connection is established and the `tts.connection.done` Server Event is received, the client should send this event to initiate audio generation.
* `type` `string` **required**
Must be set to `tts.create`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID used to identify which conversation the request belongs to. Returned by the `tts.connection.done` Server Event.
* `voice_id` `string` **required**
The ID of the voice to use. Refer to the System Voice ID List for supported voices and samples.
* `response_format` `string` **optional**
The audio format. Supported values are: `wav`, `mp3`, `flac`, `opus`, `pcm`. Also supports streaming variants: `mp3_stream`, `opus_stream`, `flac_stream`. Defaults to `mp3`.
* `sample_rate` `int` **optional**
The sampling rate of the output audio. Supported values: `8000`, `16000`, `22050`, `24000`, `48000`. Default: `24000`.
* `pronunciation_map` `object array` **optional**
Defines a pronunciation rule to annotate or override the reading of specific characters or symbols. In Chinese text, tones are represented by numbers: 1 for the first tone, 2 for the second tone, 3 for the third tone, 4 for the fourth tone, and 5 for the neutral tone.
* `tone` `string` **required**
Specific pronunciation mapping rules, separated by `/`. Example: `["omg/oh my god"]`.
* `speed_ratio` `float` **optional**
The speaking rate. Valid range: 0.5 to 2.0. Default: 1.0.
* `volume_ratio` `float` **optional**
The volume level. Valid range: 0.1 to 2.0. Default: 1.0.
* `mode` `string` **optional**
The generation mode. Supported values: `default` (character-level generation, suitable for LLM real-time streaming scenarios) and `sentence` (sentence-level generation, suitable when full sentences are already prepared). Default: `default`.
* `instruction` `string` **optional**
Global natural language guidance. Only effective when connected to the `stepaudio-2.5-tts` model. Used to set the overall emotional tone for the session. Maximum length: 200 characters.
* `markdown_filter` `bool` **optional**
Whether to enable Markdown filtering for the input text.
* `voice_label` `object` **optional**
Voice tags. Required when using a custom voice. Only one of the following fields can be set at a time: `language`, `emotion`, or `style`.
* `language` `string` **optional**
The language tag. Supported values: `Cantonese`, `Sichuanese`, `Japanese`. If not specified, the system will automatically determine whether the input text is English or Chinese.
* `emotion` `string` **optional**
Emotion tag. Supports up to 11 options such as `Happy`, `Angry`, etc. Supported values may vary by model.
* `style` `string` **optional**
Speaking or delivery style. Supports up to 17 styles. Supported values may vary by model.
⚠️ Note: The `stepaudio-2.5-tts` model does not support this field. If you are using `stepaudio-2.5-tts`, do not pass `voice_label`. Use the `instruction` field to control emotion and style instead. For other models, refer to the [Voice Tags List](/en/guides/developer/tts#voice-tags-list).
Default mode is designed for scenarios where TTS is used together with a large language model. In this mode, the system automatically buffers and segments sentences. Therefore, it does not return audio immediately; generation begins only when the accumulated input forms a complete sentence. If you need to force an immediate return, you can send `tts.text.flush`, and the model will promptly return the available audio.
Sentence mode is suitable for scenarios where the full text is already available. In this mode, the system automatically segments the text based on punctuation marks such as `. ! ?` and generates audio accordingly.
Example:
```json theme={null}
{
"type": "tts.create",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"voice_id": "lively-girl",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000,
"pronunciation_map": {
"tone": [
"LOL/laugh out loudly"
]
}
}
}
```
Example (stepaudio-2.5-tts):
```json theme={null}
{
"type": "tts.create",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"voice_id": "cixingnansheng",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000,
"instruction": "Ice-cold tone, strong pressure, slightly slow pace",
"pronunciation_map": {
"tone": [
"LOL/laugh out loudly"
]
}
}
}
```
### Generate Audio `tts.text.delta`
Client Event used to generate audio. During generation, if the TTS engine determines that the conditions for audio generation have been met, it returns a `tts.response.sentence.start` event to indicate that inference has begun. It then returns one or more `tts.response.audio.delta` events containing the audio data. After all audio for the sentence has been sent, the engine returns a `tts.response.sentence.end` event to indicate that the sentence has finished generating.
If the TTS engine determines that the conditions have not been met, no events will be returned.
* `type` `string` **required**
Must be set to `tts.text.delta`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID used to identify which conversation the request belongs to. Returned by the `tts.connection.done` Server Event.
* `text` `string` **required**
The text to be synthesized. The maximum length is 1,000 characters. Supports using `()` to pass non-spoken inline instructions. If the text itself needs to be spoken, do not wrap it in parentheses.
Example:
```json theme={null}
{
"type": "tts.text.delta",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text": "The weather is great today, and I want to learn StepFun large model technologies."
}
}
```
Example (stepaudio-2.5-tts):
```json theme={null}
{
"type": "tts.text.delta",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text": "(excited) The weather is great today, and I want to learn StepFun large model technologies!"
}
}
```
### Flush Buffer `tts.text.flush`
Forces the TTS engine to return all audio generated so far by clearing the internal buffer.
* `type` `string` **required**
Must be set to `tts.text.flush`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID used to identify which conversation the request belongs to. Returned by the `tts.connection.done` Server Event.
Example:
```json theme={null}
{
"type": "tts.text.flush",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0"
}
}
```
### Finish Audio Generation `tts.text.done`
Complete Audio Generation.
* `type` `string` **required**
Must be set to `tts.text.done`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID used to identify which conversation the request belongs to. Returned by the `tts.connection.done` Server Event.
Example:
```json theme={null}
{
"type": "tts.text.done",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0"
}
}
```
## Server Event Details
### Connection Established `tts.connection.done`
Indicates that the WebSocket connection has been successfully established.
* `event_id` `string` **required**
The unique ID of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.connection.done`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID that must be included in subsequent requests.
Example:
```json theme={null}
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.connection.done",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70"
}
}
```
### Session Created `tts.response.created`
Indicates that the session has been successfully created.
* `event_id` `string` **required**
The unique ID of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.created`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID that must be included in subsequent requests.
Example:
```json theme={null}
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.response.created",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70"
}
}
```
### Sentence Start `tts.response.sentence.start`
Indicates that the TTS engine has begun generating a new sentence.
* `event_id` `string` **required**
The unique ID of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.sentence.start`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID for the current conversation.
* `text` `string` **required**
The text content being generated in this sentence.
* `started_at` `string` **required**
The timestamp indicating when sentence generation started.
Example:
```json theme={null}
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.response.sentence.start",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text": "blah blah",
"started_at": 10292929292
}
}
```
### Receive Generated Audio `tts.response.audio.delta`
Indicates that the server is returning a chunk of generated audio.
* `event_id` `string` **required**
The unique identifier of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.audio.delta`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID must be used in subsequent requests.
* `status` `string` **required**
The generation status. Supported values are `unfinished` and `finished`.
* `audio` `string` **required**
The Base64-encoded audio data.
* `duration` `float` **required**
The duration of this audio chunk, in seconds.
Example:
```json theme={null}
{
"event_id": "42bd707a-ba16-4ddb-a751-54d84301b474",
"type": "tts.response.audio.delta",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0",
"status": "unfinished",
"audio": "BASE64 audio data",
"duration": 2.043375
}
}
```
### Sentence End `tts.response.sentence.end`
Indicates that the TTS engine has finished generating a sentence.
* `event_id` `string` **required**
The unique identifier of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.sentence.end`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID.
* `text` `string` **required**
The text content generated for this sentence.
* `ended_at` `string` **required**
The timestamp indicating when the generation of this sentence ended.
Example:
```json theme={null}
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.response.sentence.end",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text": "blah blah",
"ended_at": 10292929292
}
}
```
### Flush Start `tts.text.flushed`
Indicates that the system has received the flush command and has begun clearing the buffer.
* `event_id` `string` **required**
The unique identifier of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.text.flushed`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID that must be included in subsequent requests.
Example:
```json theme={null}
{
"event_id": "01956e8ee1b9788c95d5981b1cfdbf12",
"type": "tts.text.flushed",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0"
}
}
```
### Generation Completed `tts.response.audio.done`
Indicates that the audio generation task has been completed. After receiving this event, the connection will automatically close. Additionally, if the connection remains idle for more than 60 seconds, the system will also complete the generation and close the connection.
* `event_id` `string` **required**
The unique identifier of this event. When contacting support, providing this ID helps with troubleshooting.
* `type` `string` **required**
Must be set to `tts.response.audio.done`.
* `data` `object` **required**
Event payload.
* `session_id` `string` **required**
The session ID that must be included in subsequent requests.
* `audio` `string` **required**
The Base64-encoded audio data, containing all audio content generated in this session.
Example:
```json theme={null}
{
"event_id": "01956e8bf5067d6499cdfa0dad34f805",
"type": "tts.response.audio.done",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"audio": ""
}
}
```
### Error Event `tts.response.error`
Indicates that an error occurred during audio generation.
```json theme={null}
{
"event_id": "01956e8fdb157619a852bdf38028db45",
"type": "tts.response.error",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0",
"code": "503",
"message": "The engine is currently overloaded, please try again later",
"details": {
"error": "The engine is currently overloaded, please try again later"
}
}
}
```
## Code Example
First, run `pip install websocket-client`, and then execute the following code.
```python theme={null}
import websocket
import rel
import json
headers = {
"Authorization": "Bearer STEP_API_KEY"
}
def get_start_event(sid):
return json.dumps(
{
"type": "tts.create",
"data": {
"session_id": sid,
"voice_id": "lively-girl",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000
},
}
)
def on_message(ws, message):
data = json.loads(message)
session_id = data["data"]["session_id"]
event_type = data["type"]
if event_type == "tts.connection.done":
start_event = get_start_event(session_id)
ws.send(start_event)
print(message)
def on_error(ws, error):
print(error)
if __name__ == "__main__":
websocket.enableTrace(True)
ws = websocket.WebSocketApp(
"wss://api.stepfun.ai/v1/realtime/audio?model=step-tts-2",
header=headers,
on_message=on_message,
on_error=on_error,
)
ws.run_forever(
dispatcher=rel,
reconnect=5
)
rel.signal(2, rel.abort)
rel.dispatch()
```
```js theme={null}
const WebSocket = require('ws');
const url = 'wss://api.stepfun.ai/v1/realtime/audio?model=step-tts-2';
const headers = {
Authorization: 'Bearer STEP_API_KEY',
'Content-Type': 'application/json',
};
const ws = new WebSocket(url, {
headers: headers
});
ws.on('open', () => {
console.log('Connection established');
});
ws.on('message', (message) => {
console.log(`Message received: ${message}`);
const event = JSON.parse(message);
const session_id = event.data.session_id;
const event_type = event.type;
if (event_type === 'tts.connection.done') {
ws.send(JSON.stringify({
type: 'tts.create',
data: {
session_id: session_id,
voice_id: 'lively-girl',
response_format: 'wav',
volume_ratio: 1.0,
speed_ratio: 1.0,
sample_rate: 16000
}
}));
}
});
ws.on('error', (error) => {
console.error(`Error occurred: ${error}`);
});
ws.on('close', (code, reason) => {
console.log(`Connection closed, code: ${code}, reason: ${reason}`);
});
```
### stepaudio-2.5-tts Code Example (Python)
First, run `pip install websocket-client`, and then execute the following code.
```python theme={null}
import websocket
import rel
import json
headers = {
"Authorization": "Bearer STEP_API_KEY" # Replace with your STEPFUN API KEY
}
def get_start_event(sid):
return json.dumps(
{
"type": "tts.create",
"data": {
"session_id": sid,
"voice_id": "cixingnansheng",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000,
# [New] TTS 2.5 global emotion instruction
"instruction": "Extremely angry tone, strong pressure, slightly fast pace"
},
}
)
def on_message(ws, message):
data = json.loads(message)
session_id = data["data"]["session_id"]
event_type = data["type"]
if event_type == "tts.connection.done":
# 1. Send session creation with global instruction
start_event = get_start_event(session_id)
ws.send(start_event)
# 2. Send text with inline instruction in parentheses (max 1000 chars)
text_event = json.dumps({
"type": "tts.text.delta",
"data": {
"session_id": session_id,
"text": "(slams table) Do you think our technology at StepFun Beijing is a joke?!"
}
})
ws.send(text_event)
# 3. Send flush to force return current audio
flush_event = json.dumps({
"type": "tts.text.flush",
"data": {"session_id": session_id}
})
ws.send(flush_event)
# Print server events (including generated audio data)
print(message)
def on_error(ws, error):
print(error)
if __name__ == "__main__":
websocket.enableTrace(True)
# Use stepaudio-2.5-tts model in the connection URL
ws = websocket.WebSocketApp(
"wss://api.stepfun.ai/v1/realtime/audio?model=stepaudio-2.5-tts",
header=headers,
on_message=on_message,
on_error=on_error,
)
ws.run_forever(
dispatcher=rel,
reconnect=5
)
rel.signal(2, rel.abort)
rel.dispatch()
```