Overview
This interface provides HTTP + SSE based recognition. It’s designed to accept a single audio submission and receive transcription results pushed back via SSE.
Key Features
- One-shot audio submission
- Transcription results continuously delivered over SSE
- Supports incremental and final results
- Fits server-side calls, file transcription, and near-realtime processing
Access Overview
| Capability | HTTP + SSE |
|---|
| Audio input | One-shot submission |
| Result return | SSE streaming |
| Connection | HTTP POST |
| Session persistence | No |
| Typical client | Backend |
Service Endpoints
| Protocol | Environment | Endpoint | Notes |
|---|
| HTTP/SSE | Production | https://api.stepfun.ai/v1/audio/asr/sse | Unidirectional streaming response |
For Step Plan, use POST https://api.stepfun.ai/step_plan/v1/audio/asr/sse
HTTP Protocol
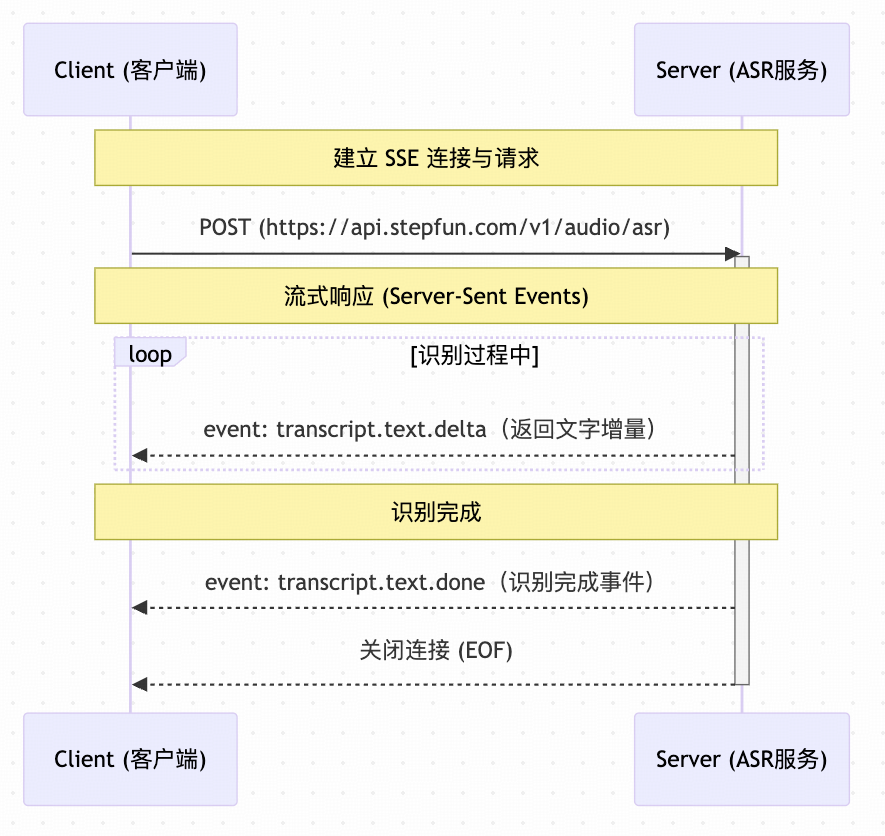
Sequence Diagram
Authentication
| Parameter | Required | Description | Example |
|---|
| Content-Type | Yes | Must be application/json | application/json |
| Accept | Yes | Must be text/event-stream | text/event-stream |
| Authorization | Yes | Authentication token | Bearer sk-xxxx |
{
"audio": {
"data": "audioData",
"input": {
"transcription": {
"language": "zh",
"hotwords": ["hotword1", "hotword2"],
"model": "stepaudio-2.5-asr",
"enable_itn": true,
"enable_timestamp": true
},
"format": {
"type": "pcm",
"codec": "pcm_s16le",
"rate": 16000,
"bits": 16,
"channel": 1
}
}
}
}
Parameters
| Path | Type | Description | Example |
|---|
audio.data | string | Base64-encoded audio data | "audioData" |
audio.input.transcription.language | string | Recognition language | "zh" |
audio.input.transcription.hotwords | array | Hotword list, e.g. ["hotword1", "hotword2"] | ["hotword1", "hotword2"] |
audio.input.transcription.model | string | Model name. Supports stepaudio-2.5-asr, stepaudio-2-asr-pro | "stepaudio-2.5-asr" |
audio.input.transcription.enable_itn | bool | Whether to enable ITN text normalization (default true) | true |
audio.input.transcription.enable_timestamp | bool | Whether to return audio timestamps for the recognized text (default false) | true |
audio.input.format.type | string | Audio container format. Supports ogg, mp3, wav, pcm | "pcm" |
audio.input.format.codec | string | Encoding format; when type=pcm, typically pcm_s16le | "pcm_s16le" |
audio.input.format.rate | int | Sample rate; required for pcm, optional for others | 16000 |
audio.input.format.bits | int | Bit depth; required for pcm, optional for others | 16 |
audio.input.format.channel | int | Channel count; required for pcm, optional for others | 1 |
Compatibility notes:
- For backward compatibility, the SSE endpoint still accepts
step-asr-1.1-stream as the model value, which is equivalent to stepaudio-2.5-asr.
- The
full_rerun_on_commit parameter (second-pass recognition correction) is no longer supported on SSE. If legacy clients still send it, the server silently ignores it and recognition proceeds normally.
- Audio data must be Base64-encoded.
- Supported audio formats:
ogg, mp3, wav, pcm.
- When the audio format is
pcm, rate, bits, and channel are required.
- When the audio format is
ogg, mp3, or wav, rate, bits, and channel are optional.
SSE streaming response with the following event types:
Delta Event (transcript.text.delta)
Incremental transcription text.
{
"type": "transcript.text.delta",
"meta": {
"session_id": "sse_1642694400123456789",
"timestamp": 1642694400123
},
"delta": "recognized ",
"item_id": "item_xxx",
"content_index": 0,
"start_time": 0,
"end_time": 500
}
| Field | Type | Description |
|---|
type | string | Event type. Fixed as transcript.text.delta |
meta.session_id | string | Session ID |
meta.timestamp | int64 | Server-side event Unix timestamp (ms) |
delta | string | Incremental transcription text |
item_id | string | Conversation item ID |
content_index | int | Content index |
start_time | int64 | Audio start time corresponding to the recognized text (ms) |
end_time | int64 | Audio end time corresponding to the recognized text (ms) |
When the request parameter audio.input.transcription.enable_timestamp=true, the Delta event response includes the additional fields item_id, content_index, start_time, end_time. meta.timestamp is the server-side event Unix timestamp; start_time / end_time are the position of the recognized text inside the audio. All three are in milliseconds.
Done Event (transcript.text.done)
Final transcription text is ready.
{
"type": "transcript.text.done",
"meta": {
"session_id": "sse_1642694400123456789",
"timestamp": 1642694400456
},
"text": "The complete recognized text",
"usage": {
"type": "realtime_asr",
"input_tokens": 1000,
"input_token_details": {
"text_tokens": 0,
"audio_tokens": 1000
},
"output_tokens": 50,
"total_tokens": 1050
}
}
| Field | Type | Description |
|---|
type | string | Event type. Fixed as transcript.text.done |
meta.session_id | string | Session ID |
meta.timestamp | int64 | Unix timestamp (ms) |
text | string | Complete transcription text |
usage | object | Usage statistics |
Error Event (error)
Returned when recognition fails.
{
"type": "error",
"meta": {
"session_id": "sse_1642694400123456789",
"timestamp": 1642694400789
},
"message": "Error description"
}
| Field | Type | Description |
|---|
type | string | Event type. Fixed as error |
meta.session_id | string | Session ID |
meta.timestamp | int64 | Unix timestamp (ms) |
message | string | Error description |